-
Type:
Bug
-
Status: Closed
-
Priority:
 Blocker
Blocker
-
Resolution: Fixed
-
Affects Version/s: 1.19
-
Fix Version/s: 1.20
-
Component/s: Basic-Other, Basic-Protein
-
Story Points:5
-
Tests Type:GUI automatic
-
Sprint:DEV-02/12/2015
-
Affect Type:Userdefined
The issue must be fixed and tested until Nov. 18!!
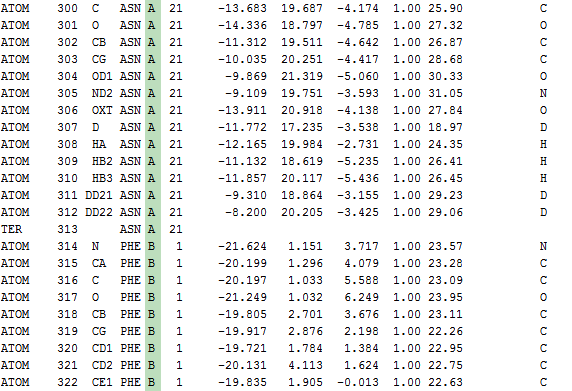
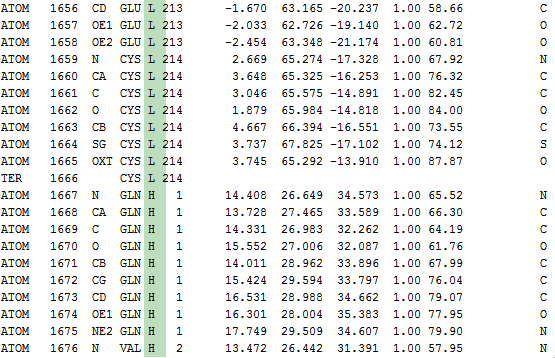
In the current UGENE version names of chains, loaded from a PDB file, are numerical. This is incorrect. The names are available in the PDB format and must be used in the UGENE GUI - use chain identifier field from the "ATOM" records.
For details see the use cases below, the attached screenshots, and the format specification:
http://www.wwpdb.org/docs/documentation/file-format/PDB_format_1996.pdf (p.174 - the chapter about "ATOM")
Use case 1:
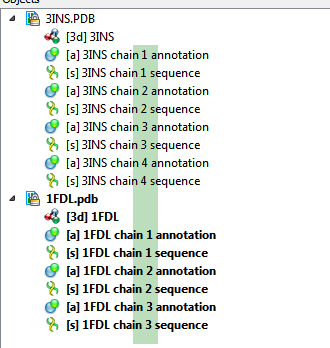
- Open a PDB file with several "MOLECULE" records (e.g. 1FDL).
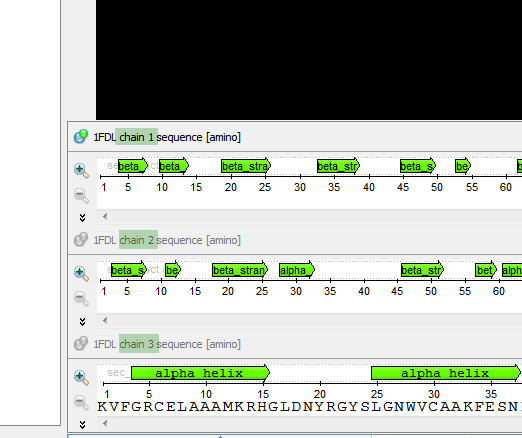
Expected state: The correct chain names are shown in the Project View and in each single-sequence view of the Sequence View. - Open an annotation node in the Annotations Editor to see its qualifiers.
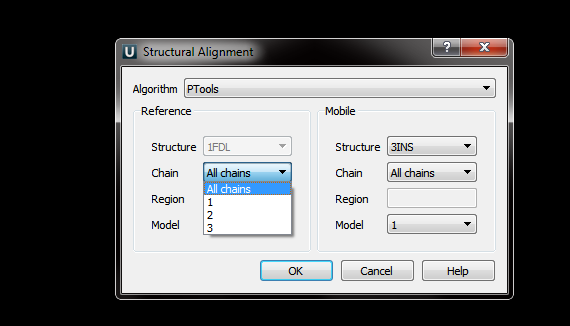
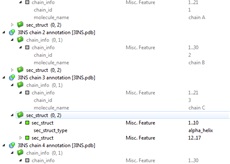
Expected state: There is "molecule_name" filed. It has a correct molecule name, read from the PDB file header, NOT the chain name. - Select "Structural Alignment > Align With" item in the context menu.
Expected state:- The correct chain names are available in the "Chain" menu.
Use case 2:
The same as UC1, but use a PDB file with molecules that have several chains, i.e. the comma-separated list of chain identifiers (e.g. 3INS).


- relates to
-
-

- Closed
-