-
Type:
Improvement
-
Status: Closed
-
Priority:
 Major
Major
-
Resolution: Fixed
-
Affects Version/s: 1.32
-
Fix Version/s: 33
-
Labels:
-
Story Points:3
-
Tests Type:Functional/Unit
-
Sprint:DEV-33-3
-
Affect Type:Userdefined
Scenario:
- Open the attached "ngs_data_qc.uwl" workflow.
- Select the "Read Illumina PE Reads" element, specify several pairs of FASTQ files as input. See, for example, files for this issue on the file server.
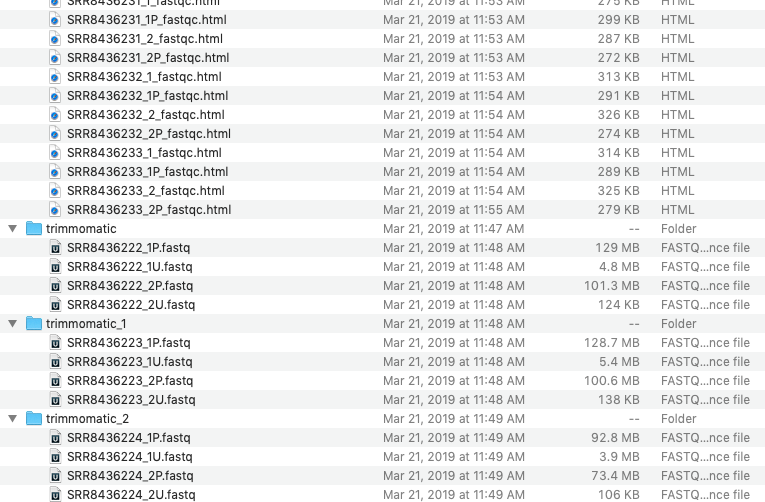
Current result: all FastQC HTML reports are saved into one output folder "FastQC", a separate "trimmomatic" folder is created for each pair of FASTQ files (i.e. "trimmomatic", "trimmomatic_1", "trimmomatic_2", etc.).
Expected result: like for FastQC there should be one folder for Trimmomatic output files, it should be called "Trimmomatic".
The output folder should be created in a context of a dataset. So, there should be still several output folders, if the input files are put in different datasets.
Check the issue for SE reads also.
Also, rename other folders in the "run" output folder, so that the name takes into account upper-case characters in the tool name, e.g. "Kraken", "CLARK", "DIAMOND", "MetaPhlAn2", etc.